



インデックス投資を行う上で、そのインデックスや具体的な投資対象となるETFの銘柄構成を知ることは重要です。
さらに、VOOとVTIのように似たインデックスで比較するときは、何が共通していて、何が違っているのか考えてみることも重要です。
今回は、そんな差分比較をベン図を使って直感的にやってみます。
きっかけ
ETFやインデックスのベン図を書くというアイデアを知ったのは、Twitterでハルさんの以下のようなツイートを見たことでした。
こちらは高配当で人気のSPYDや、昨今のハイテク隆盛で人気のQQQなど、今を時めく米国株ETFの構成銘柄でベン図を書いています。
円の大きさで構成銘柄の多さを、円の重なりで構成上の類似性を直感的に掴むことができ、こういう視覚的アプローチはとてもいいですね。
ハルさんはこのツイートの中でも「他のETFも見たい方はリクエストください」と仰っていますが、やはり自分でしょーもないところ含めて色々やってみたいので、自分でもベン図作りにチャレンジすることにしました。
難易度

先に方法だけ端的に触れておくと、
- 銘柄数の重複をコマンドラインでカウント
- Pythonのベン図ライブラリを使って描画
する話なので、この2行を見て「ははーん」と思える方は簡単にできると思います。
私も本業はITエンジニアなので特に躓くことはありませんでしたが、そもそもコマンドラインに触れたことがない場合にはちょっとハードルが高いかもしれません。
ベン図の書き方

それでは本編です。
以下の3ステップでできます。
- 事前準備(データ/環境)
- 銘柄数の重複をカウント
- Pythonを使ってベン図を作成
事前準備(データ/環境)
まずは実際の作業をする前に少し準備をします。
データの準備
ハルさんが米国株でやっていて、車輪の再発明をするのもあれなので、私は日本株でやってみます。
具体的には代表的なインデックスである、
- 日経225
- TOPIX
- JPX日経400
ですね。
これらの構成銘柄はググったらすぐ見つかるので、構成銘柄の証券コードだけを記載した、以下のようなファイルをそれぞれ作っておきます。
# NIKKEI225.txt の場合
1332
1333
1605
1721
1801
1802
...
9984このとき、記載する証券コード(日本株の場合)やティッカー(米国株の場合)は昇順または降順で各ファイル同じようにソートされているようにしてください。
というわけで、データとして
- NIKKEI225.txt
- TOPIX.txt
- JPX400.txt
を準備しましょう。
コンピュータ上で日本語を使うと何かと面倒なのでアルファベットだけにしておくと楽です。(どうしても日本語を使いたい方は記事末尾を参考にどうぞ)
環境の準備
実際のグラフ描画はPythonで行いますが、利用するvenn3は標準で導入されていないと思うので、手元の環境に導入しておいてください。
私はWSL2を使ったUbuntu on Windowsでやっていますが、MacやLinuxでも同様ですし、Python環境なのでそのままWindows上で動かすことも一応できると思います。
今はWindowsでもWSL2を使って簡単にCLI環境が手に入るので楽になったなと感じます。
具体的には、Pythonのpipを使ってインストールできるので、
あたりを参考にしてpipを導入し、以下のコマンドでライブラリをインストールしましょう。
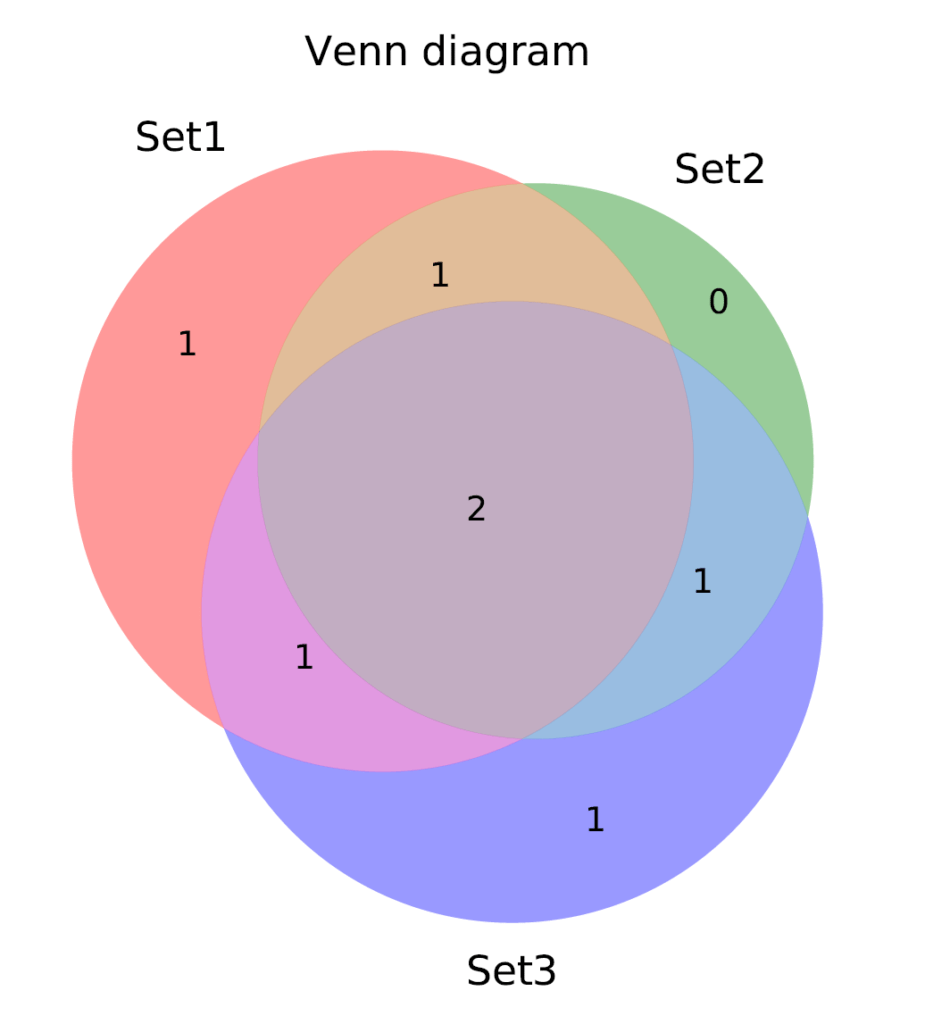
# pip install matplotlib-venn導入できたら、動作確認として以下のファイル venn_test.py を作り、Pythonから実行してみてください。
from matplotlib_venn import venn3
import pylab as plt
set1 = set([1,2,3,4,5])
set2 = set([1,4,5,6])
set3 = set([1,4,6,8,6,3])
venn3([set1,set2,set3],set_labels=("Set1","Set2","Set3"))
plt.title("Venn diagram")
plt.savefig("venn_sample.pdf",format="pdf")# python venn_test.pyそうすると、実行ディレクトリに venn_sample.pdf というファイルができていますので、その中身が以下のように描けていれば準備完了です。ライブラリ様様ですね。
Pythonを使ってベン図を作成
実際にベン図を書いていきましょう。
先ほどサンプル実行したのでほとんど同じですが、今回の例であれば、次のようなプログラム venn.py を作ります。
from matplotlib_venn import venn3
import pylab as plt
import sys
# ベン図名の取得
VENN_NAME=sys.argv[1]
# 対象名の取得
A_NAME=sys.argv[2]
B_NAME=sys.argv[3]
C_NAME=sys.argv[4]
# ベン図集合の生成
FA = open(A_NAME + ".txt")
A_SET = set(FA.read().splitlines())
FA.seek(0)
A_COUNT = sum(1 for row in FA)
FA.close()
FB = open(B_NAME + ".txt")
B_SET = set(FB.read().splitlines())
FB.seek(0)
B_COUNT = sum(1 for row in FB)
FB.close()
FC = open(C_NAME + ".txt")
C_SET = set(FC.read().splitlines())
FC.seek(0)
C_COUNT = sum(1 for row in FC)
FC.close()
# ラベルの生成
A_LABEL = A_NAME +"(" + str(A_COUNT) + ")"
B_LABEL = B_NAME +"(" + str(B_COUNT) + ")"
C_LABEL = C_NAME +"(" + str(C_COUNT) + ")"
# ベン図の出力
venn3([A_SET,B_SET,C_SET],set_labels=(A_LABEL, B_LABEL, C_LABEL))
plt.savefig(VENN_NAME + ".pdf", format="pdf")上のプログラムは今回の日本株ベン図に即した名前や数字を入れていますが、適宜調べたい対象の名前や個数で書き換えてください。
あとは、これをファイル名等を指定した上で動かしてみると、実行ディレクトリに指定したファイル名、形式のベン図(今回は JP_ETFs.pdf )が出力されます。
### 出力ファイル名 / ファイル1 / ファイル2 / ファイル3
# python venn.py JP_ETFs NIKKEI225 TOPIX JPX400
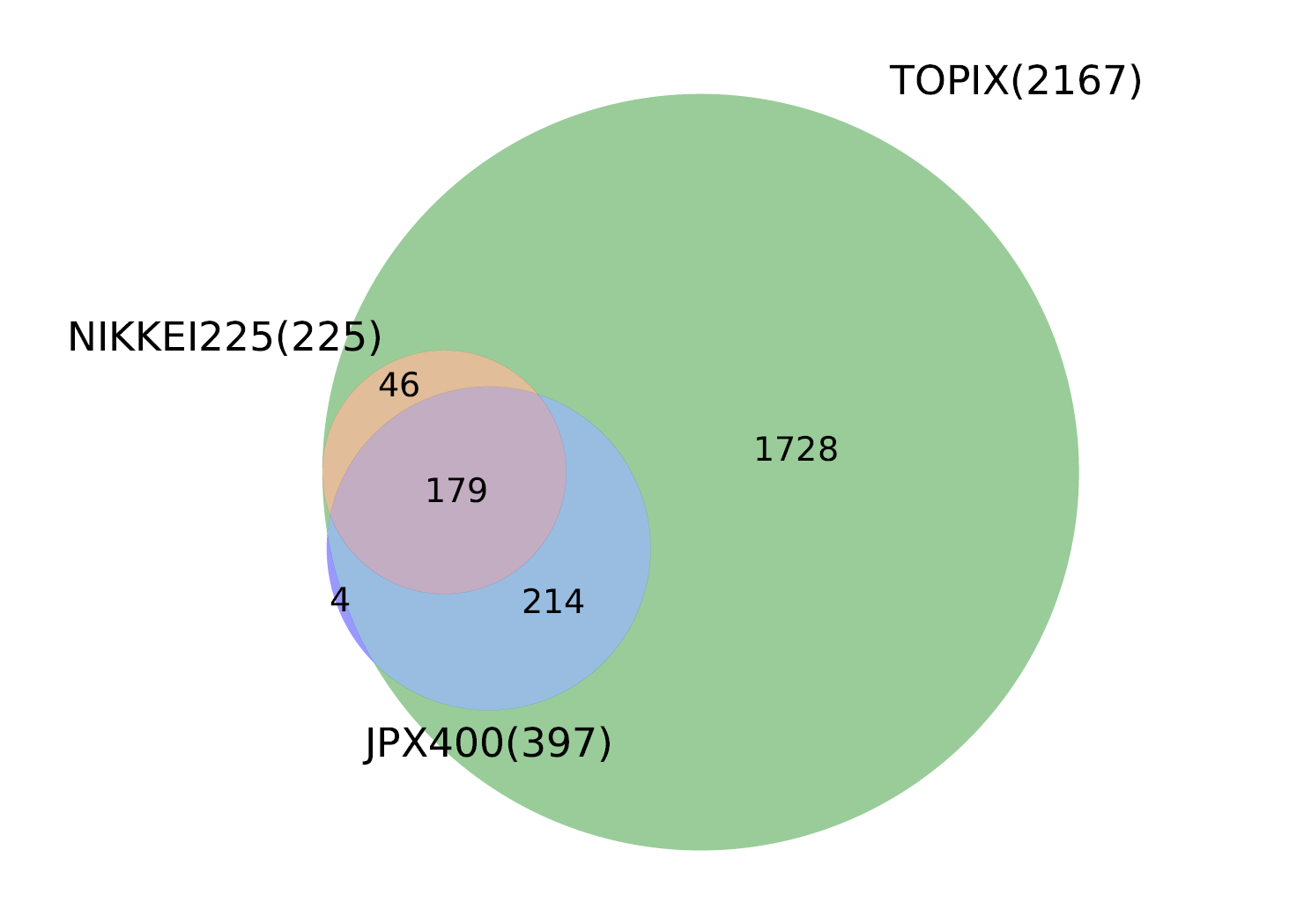
これを見ると「東証1部上場銘柄の全てを含むTOPIX」というのがよくわかりますね。
まとめ
今回はTwitterでたびたび話題になるベン図の書き方をまとめてみました。
今回やったのはあくまで単純な銘柄数の重複なので、組入比率というウェイトを加味せず、単純な重複を可視化したに過ぎません。
そのため、このベン図をもって実際にそのインデックスやETFが何であるかを理解するにはまだまだ遠いのですが、直感的に類似性を掴む観点ではとてもわかりやすくていいと思います。
実際、今回この日本株でやってみて、TOPIXと日経225が225銘柄重複しているのはいいにせよ、スマートベータ的に組まれているJPX日経400との重複が179しかないのは意外でしたね。
投資会社の長期レポートによれば、今後は米国株式より日本株式のリターンが見込まれるとされていますが、そうしたリターンとインデックスを通じた市場運営は切っても切り離せないと思いますので、JPX日経400の勉強や、東証再編の動きはさらに追っていきたいです。
補足
今回は「日本語を使うと何かと面倒だから」という理由で日本語を排除していますが、もちろん色々やれば日本語を標示させることが可能です。
気になる方は以下のページを参考にしてみてください。
あとは、今回のベン図はPDFで出力していますが、これをpngなど別のフォーマットで出力させることも可能です。
グラフ描画に使ったPythonコード末尾にある savefig メソッドにパラメータを渡すことで色々変えられますので、必要に応じてやってみてください。
しかしまぁ、簡単といえば簡単ですが、ITエンジニアやってなかったらさすがに心折れてる気もしますね…。
















